AWS Glue
: 전처리(ETL)를 주 목적으로 한 서비스

- 위 데이터 분석 파이프라인의 저장 부분에서 데이터 전처리(ETL)를 담당하고 분석을 용이하게 하는 역할을 한다.
AWS Glue 데이터 카탈로그
: 모든 데이터 자산의 정형 및 운영 메타 데이터를 저장하는 중앙 레포지터리를 말하는데, 크롤링 혹은 직접 저장, 참조를 통해 메타 데이터를 데이터 카탈로그화 한다.
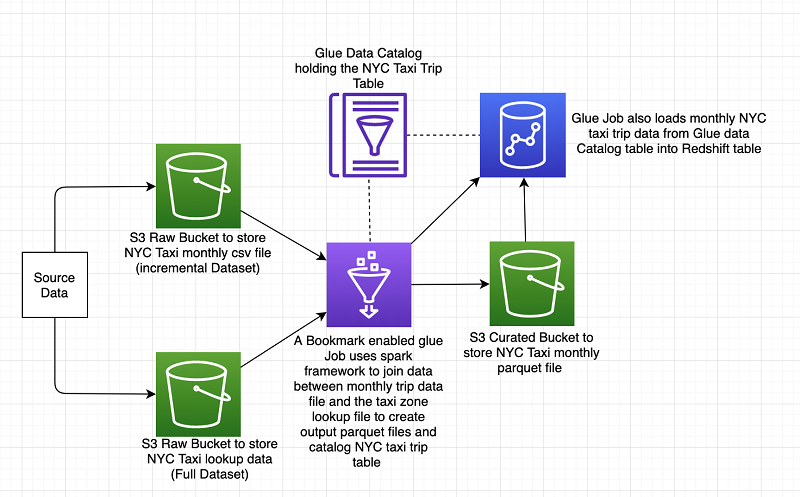
크롤러
: 하나의 웹페이지에서 다른 웹페이졸 연결되는 링크를 따라가며 웹 사이트를 자동으로 검색하고 스캔하는데 사용되는 프로그램이다.

AWS Glue의 Job
: Glue의 작업은 아래 3가지 방법으로 개발이 가능하다. 개인의 개발 방법과 리소스 사용 방식에 따라 적절하게 선택하면 된다.
1. Glue Studio (AWS 관리 콘솔)
2. SageMake Studio (AWS 관리 콘솔)
3. 로컬 (로컬 PC 혹은 EC2)
AWS SageMaker
: AWS의 Machine Learning 서비스
조직별 엑세스 제어의 핵심
: 사용자와 객체에 대한 태그 지정으로 엑세스 제어를 실현한다. 관리자로써 태그의 사용은 정말 중요하다.
관리하는 테이블의 수가 방대해지면, 행기반 / 열기반 관리 방식으로는 관리가 불가능하다.
따라서 태그 기반으로 관리하면 원활한 관리가 가능하다.
쿠버네티스에서도 태그와 비슷하게 레이블(label)로 스케줄링 등과 같은 기능에 사용한다.
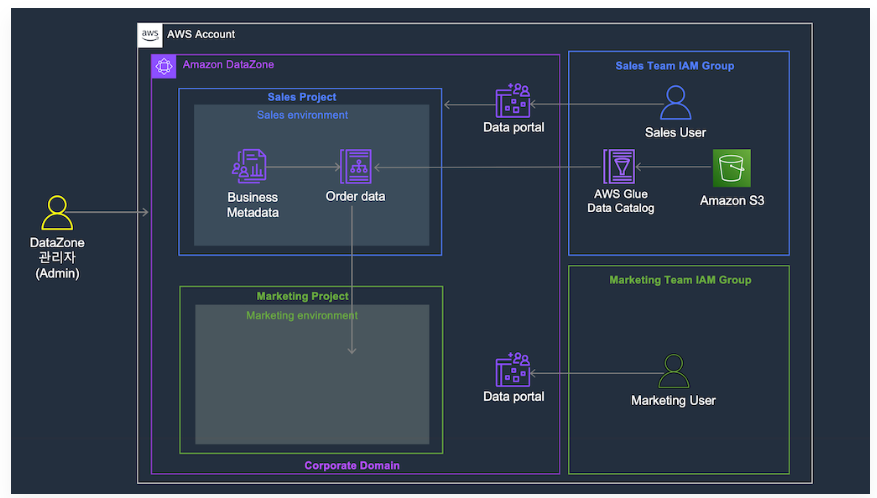
AWS Lake Formation
: Lake Formation을 사용하면 데이터 메시 환경을 구현하는데 유용하다.
- 데이터 메시 환경
: 조직 내에서 각각의 부서들이 사용하는 여러 개의 테이블이 데이터를 서로 참조하고 공유하는 환경을 의미한다.
Data Zone
: 데이터 생산자와 데이터 소비자 모두에게 협업 도구를 제공하는 완전 관리형 서비스


실습 데이터 생산자 작업 (1~6까지 예상 사용자 : 생산자)
실습 Flow

소개
1. 실습 대상자와 전제조건

2. 실습의 목적

3. 사용하는 AWS 서비스

4. 실습에서 발생하는 요금

5. 주의사항

실습의 전체 흐름
1. Amazon DataZone 도메인 생성

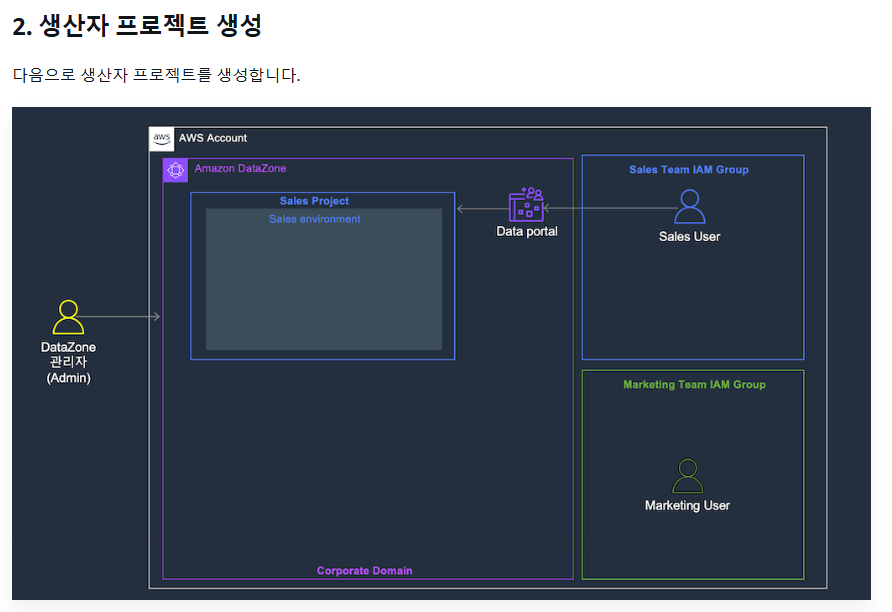
2. 생산자 프로젝트 생성
3. 게시할 데이터 생성

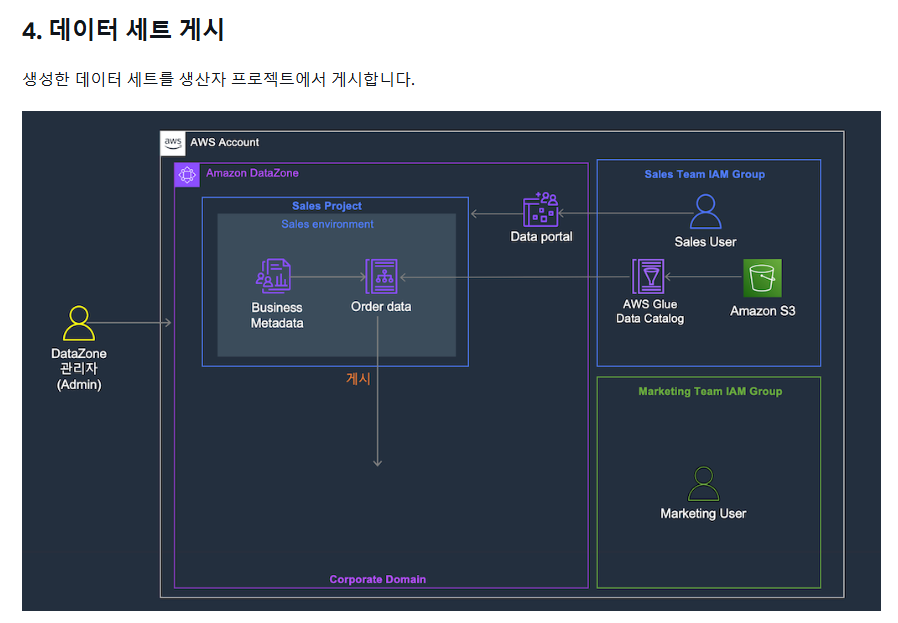
4. 데이터 세트 게시
5. 소비사 프로젝트 생성 및 게시된 데이터 세트 구독

실습 본문
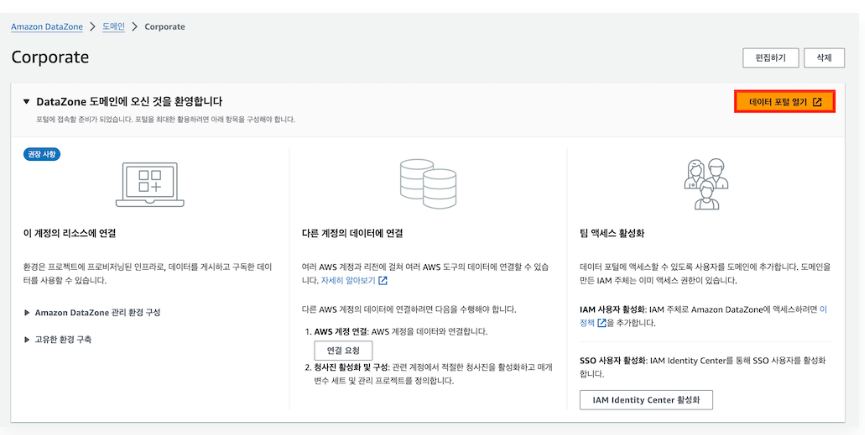
1. Amazon DataZone 도메인과 데이터 포털 생성

1) DataZone 관리 페이지 열기

2) 도메인 생성
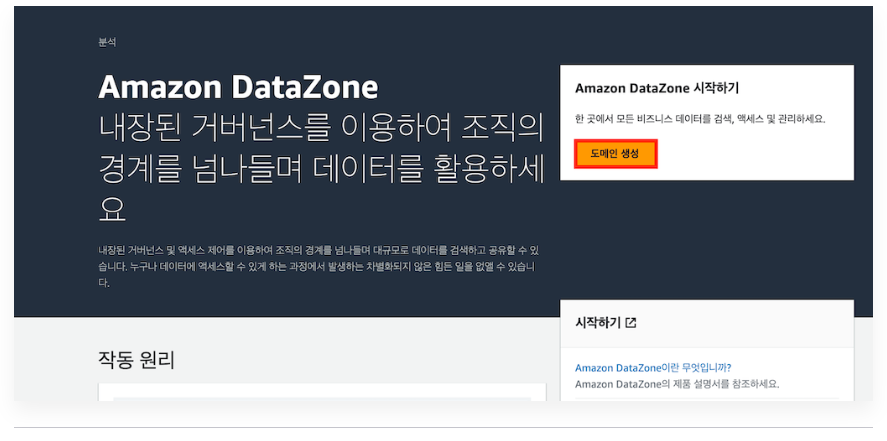
- 도메인 생성 마법사에서 도메인 생성

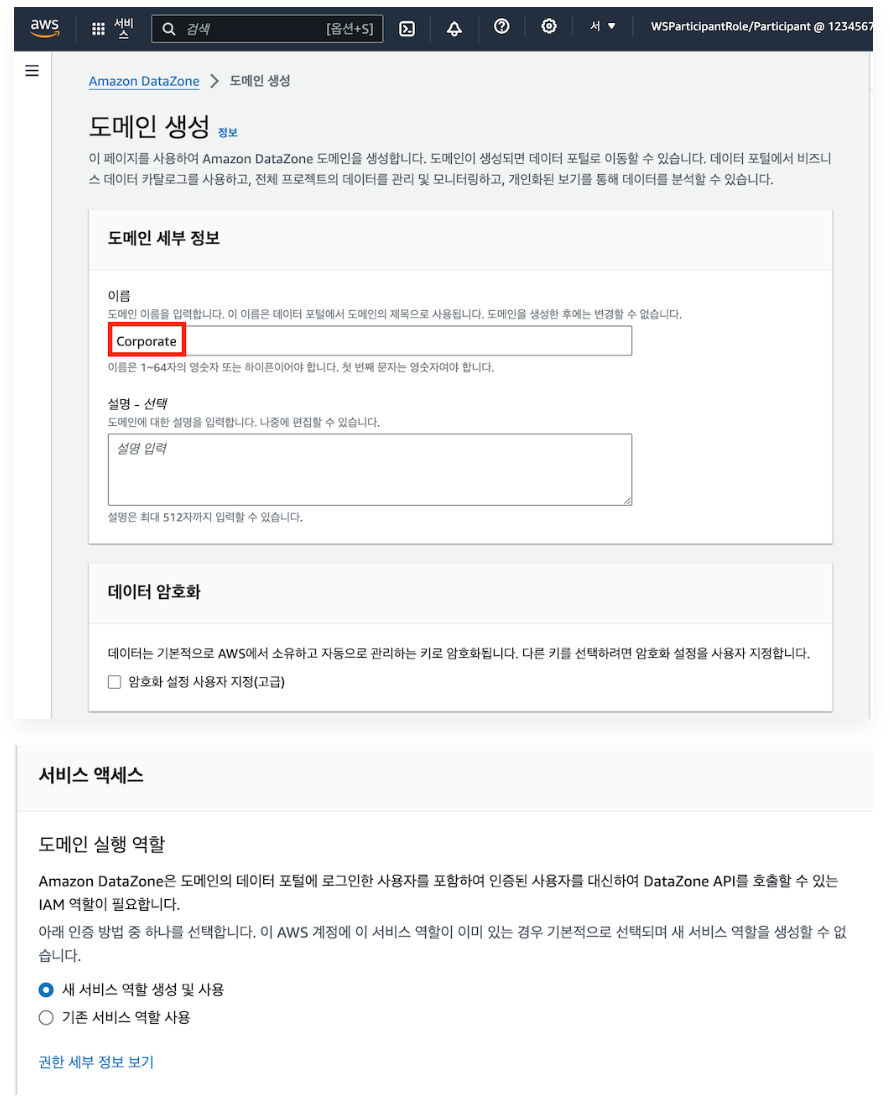
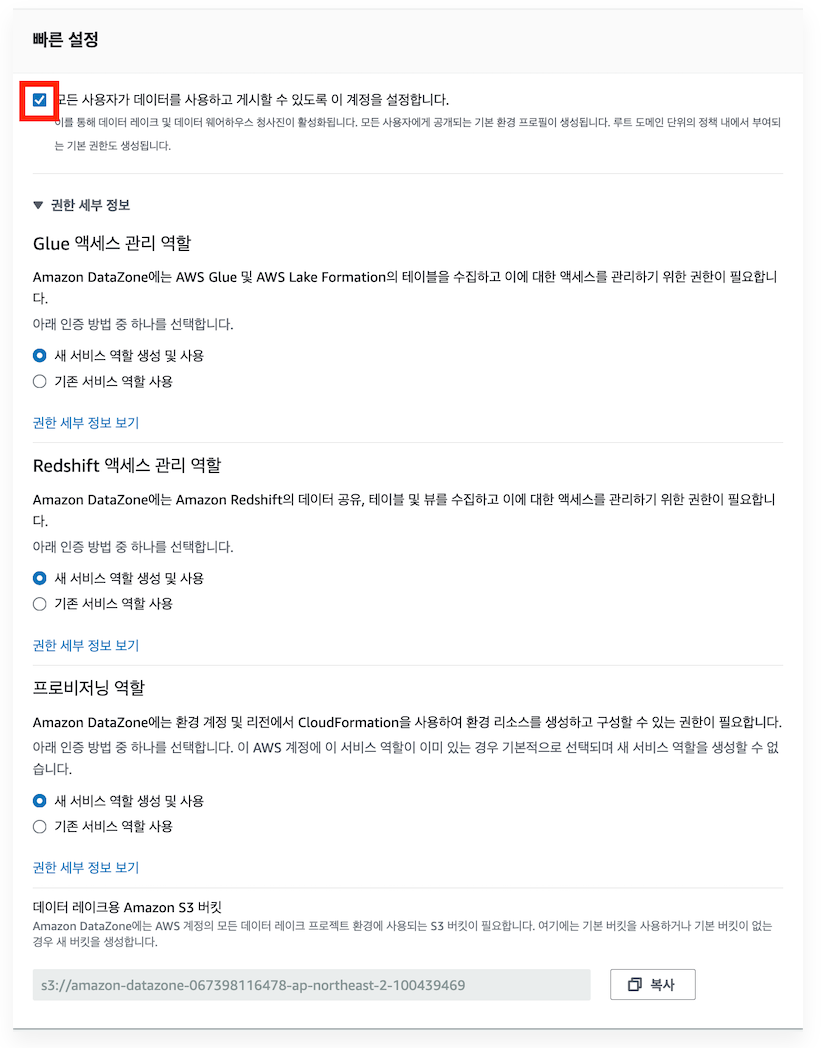
- 도메인 생성 확인 후 하이브리스 액세스 모드 활성화


=> 편집 클릭

=> 체크박스 체크하여 하이브리드 액세스 모드 활성화
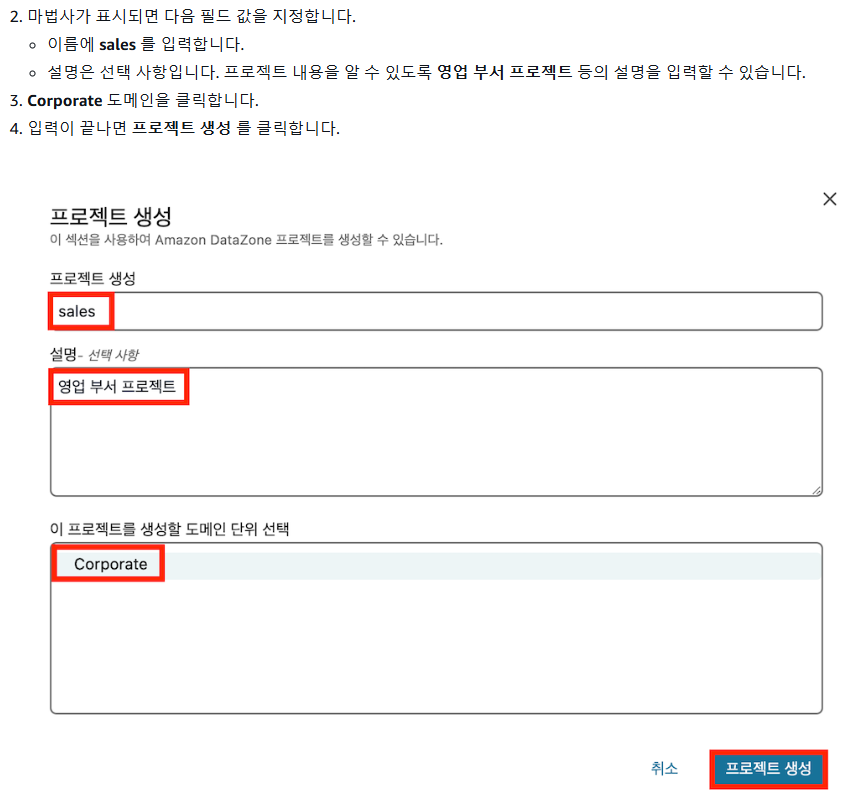
2. 생산자 프로젝트 생성

1) 프로젝트 생성화면 이동 후 새 프로젝트 생성

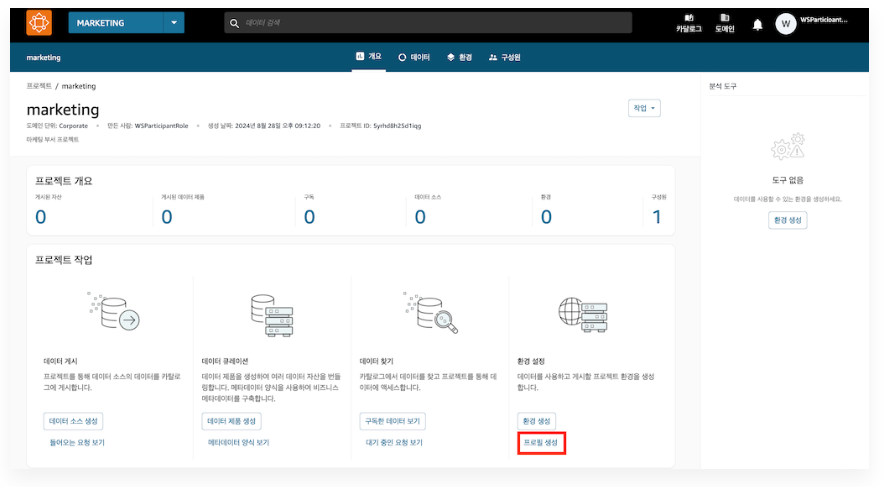
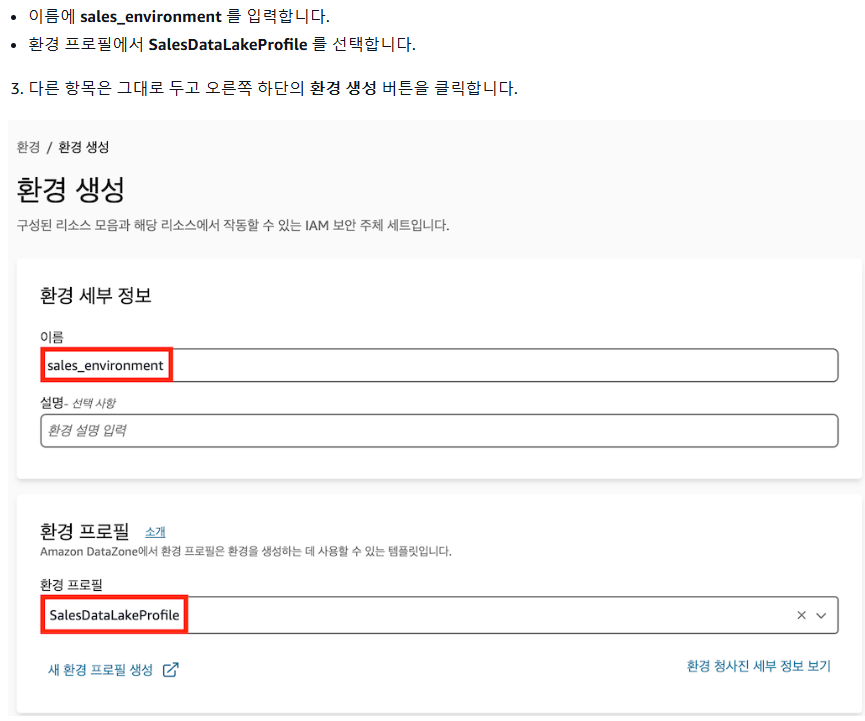
3. 프로젝트 환경 생성

1) 환경 프로필 생성
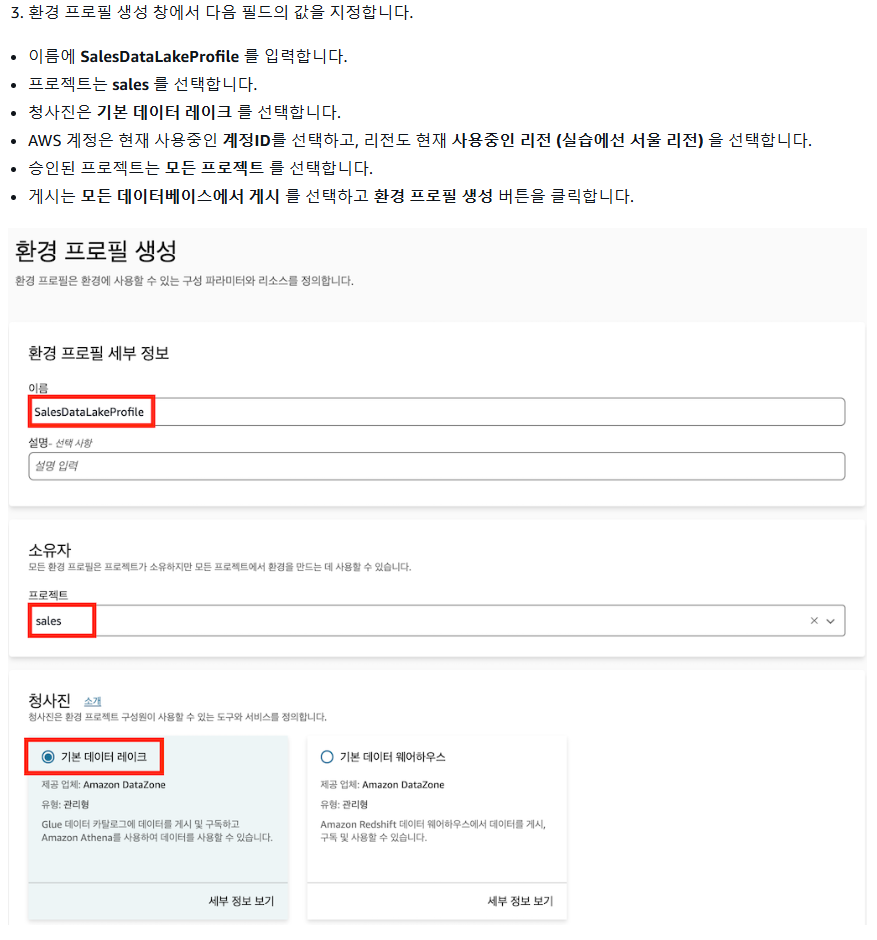
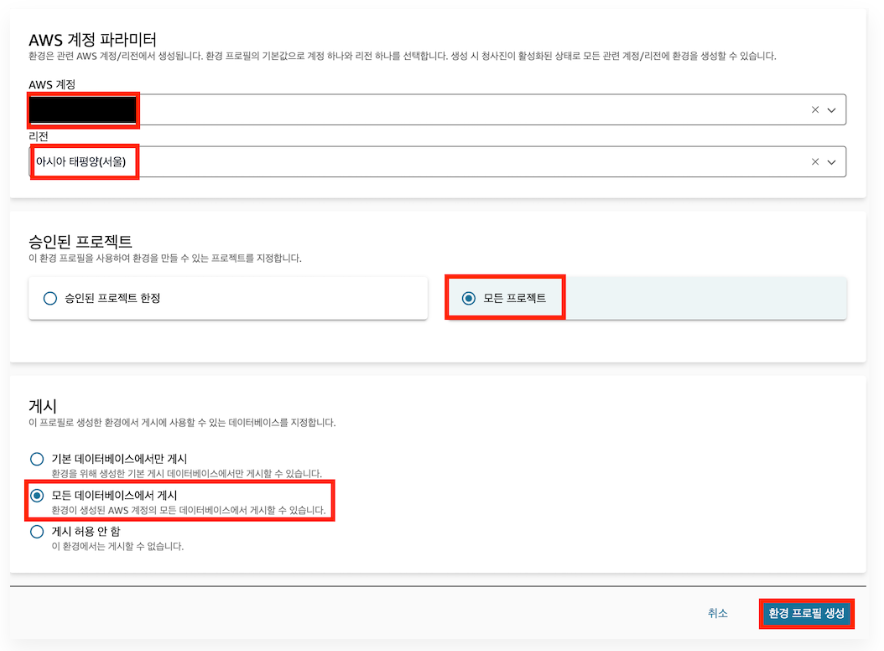
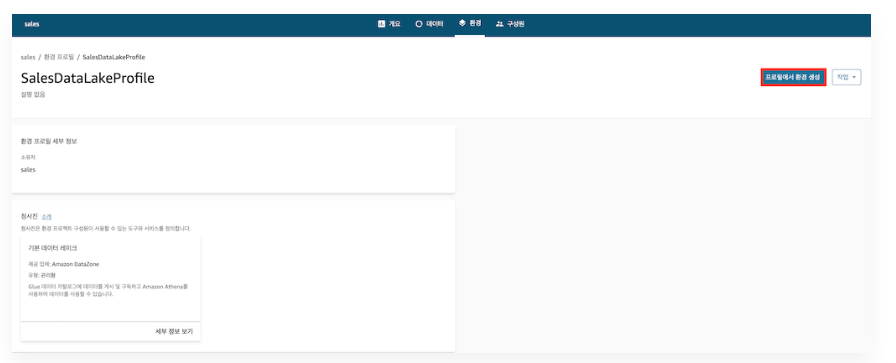
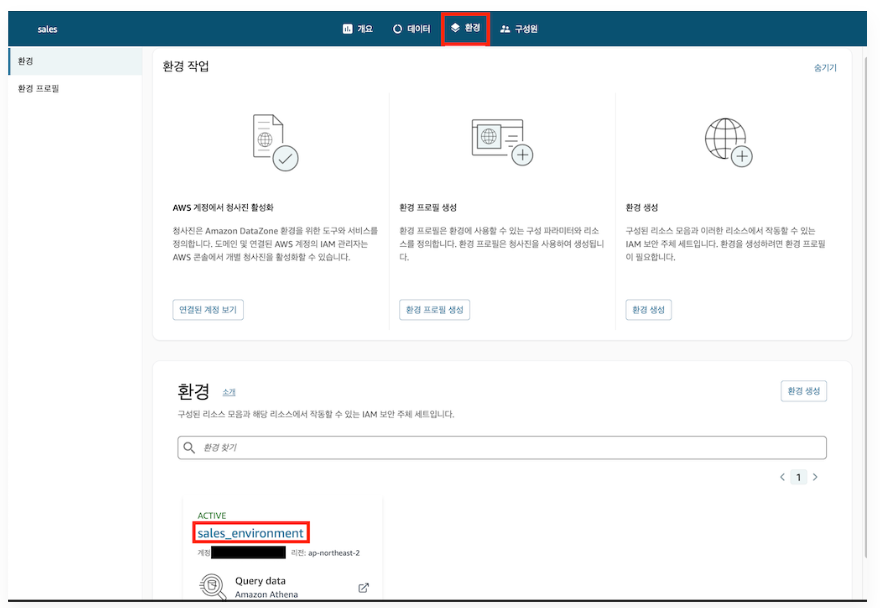
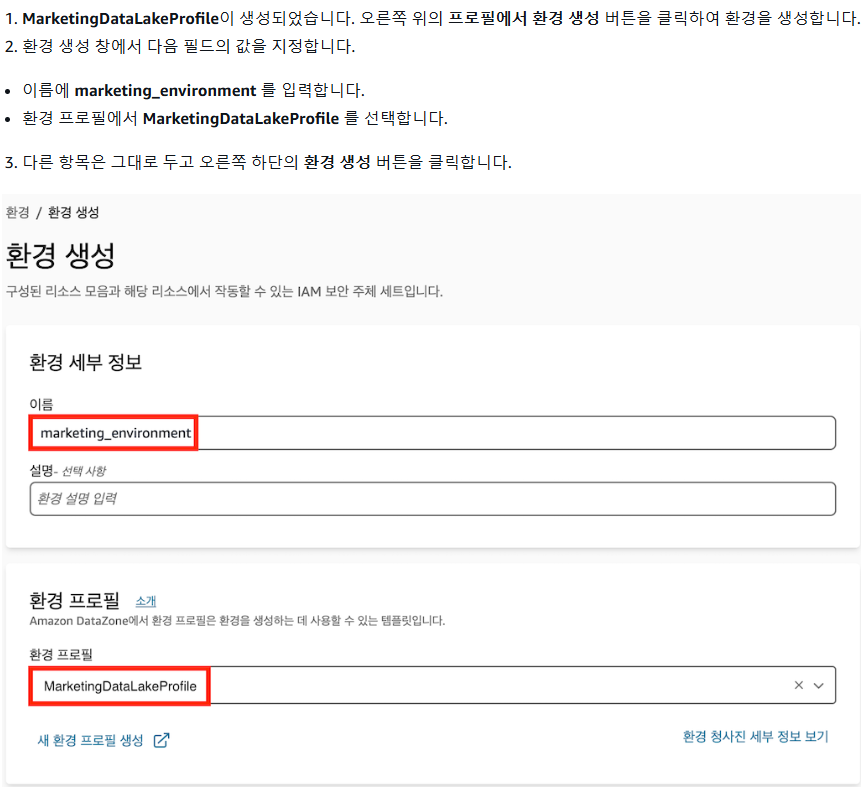
2) 환경 생성


4. DataZone에서 게시할 데이터 생성

1-1) Amazon S3에 데이터 업로드
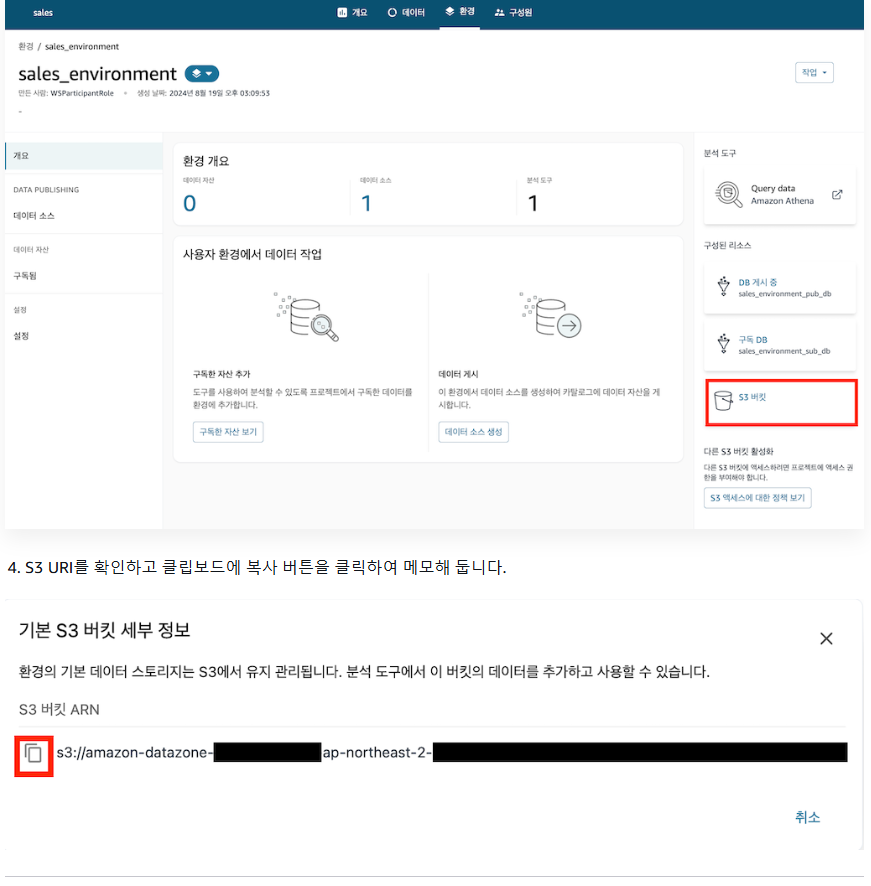
1-2) S3 관리 콘솔 이동

1-3) 데이터 파일 업로드용 폴더 생성

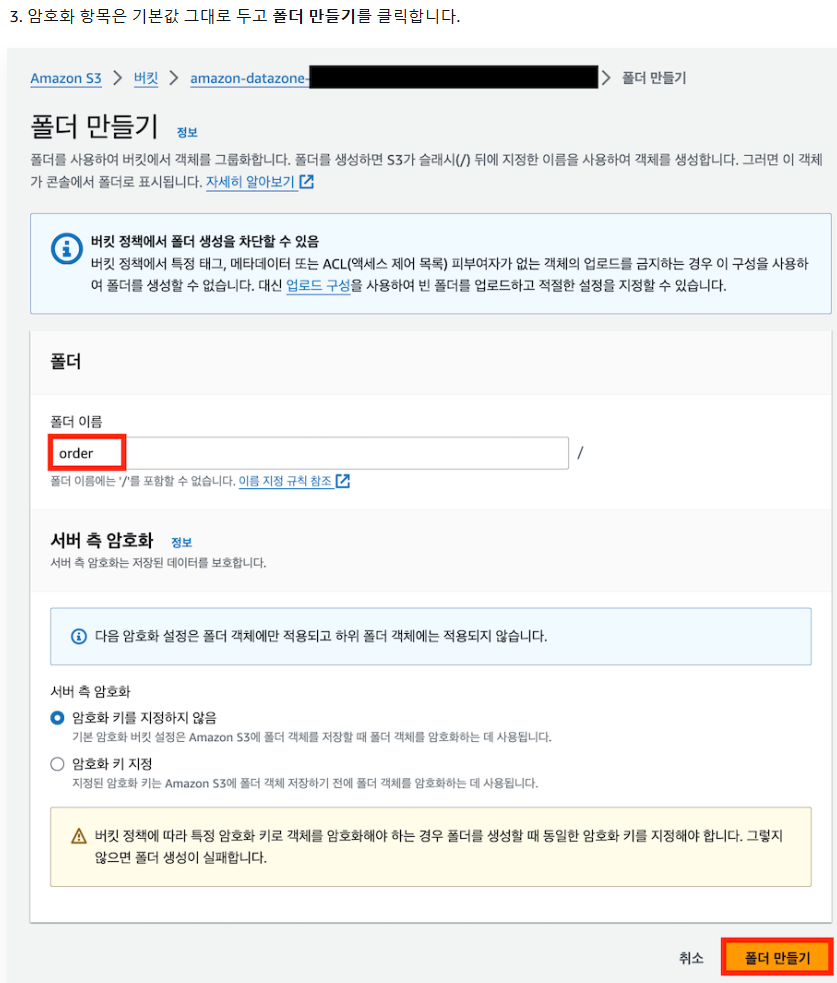

=> 폴더 생성 확인
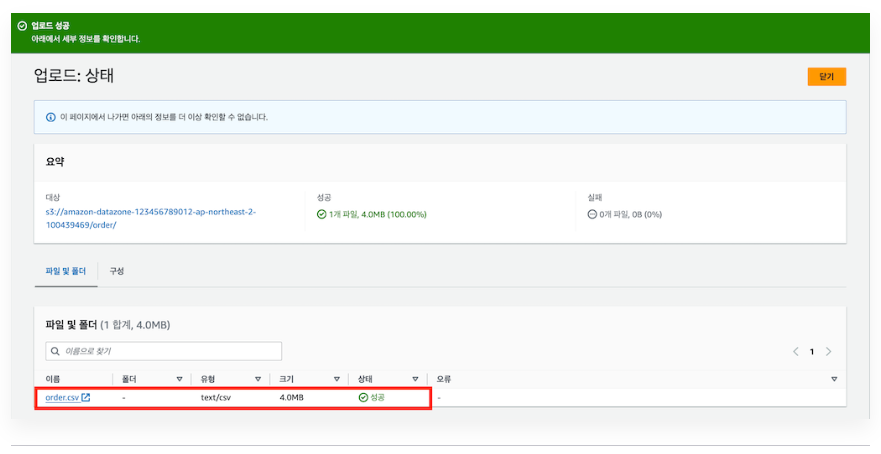
1-4) 데이터 파일 가져오기 및 업로드

2-1) Glue Crawler 관리 콘솔로 이동

2-2) Crawler 생성 -> 기본 정보 입력 -> S3 저장소 지정
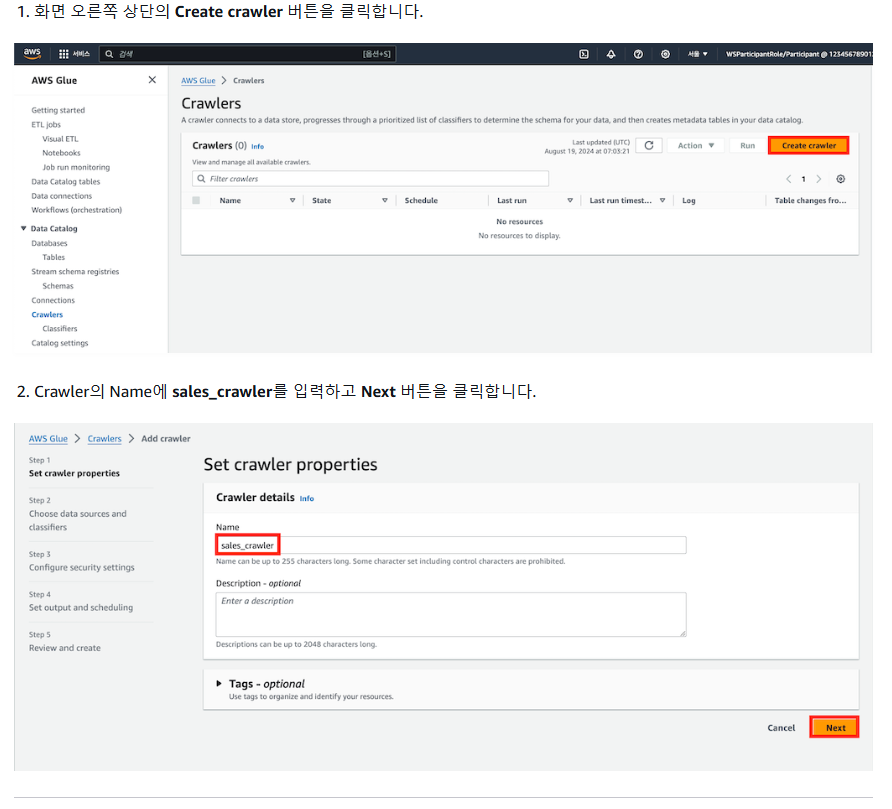


=> S3 저장소 지정

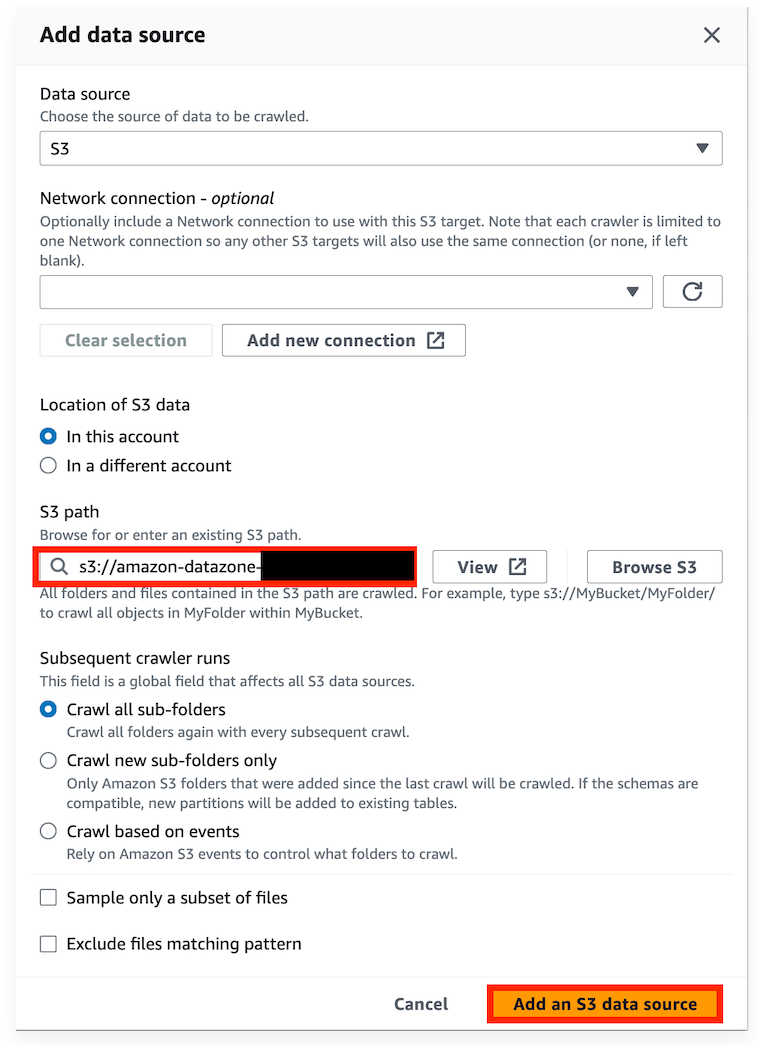
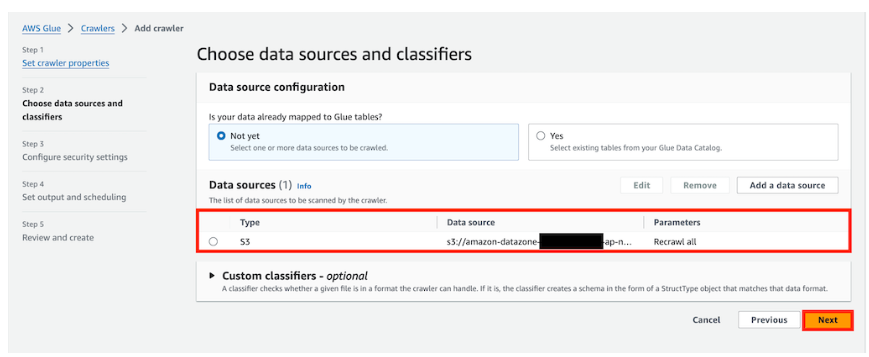
2-3) Crawler 생성 : IAM 권한 지정
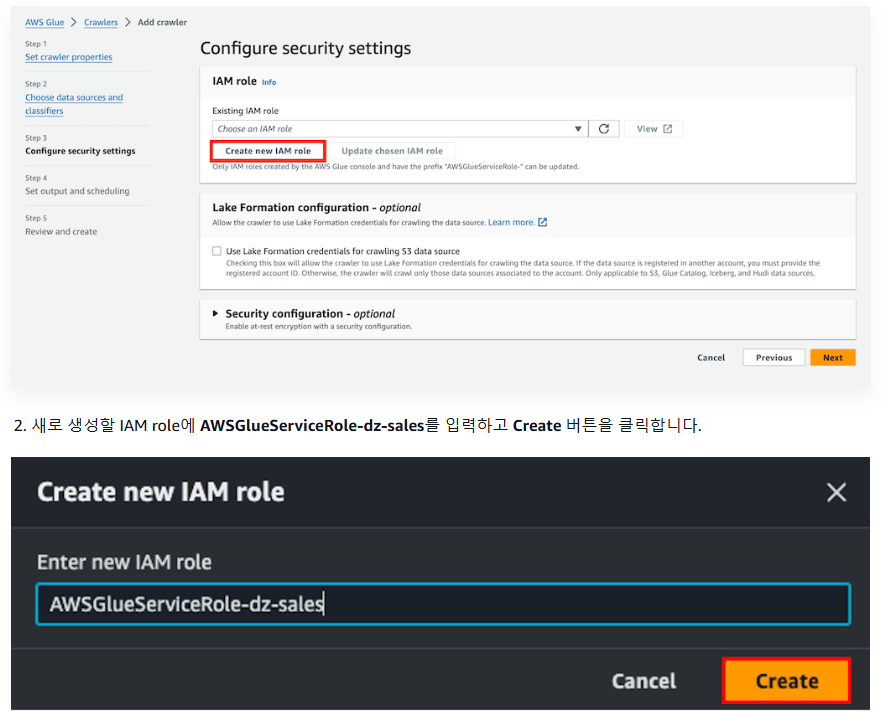
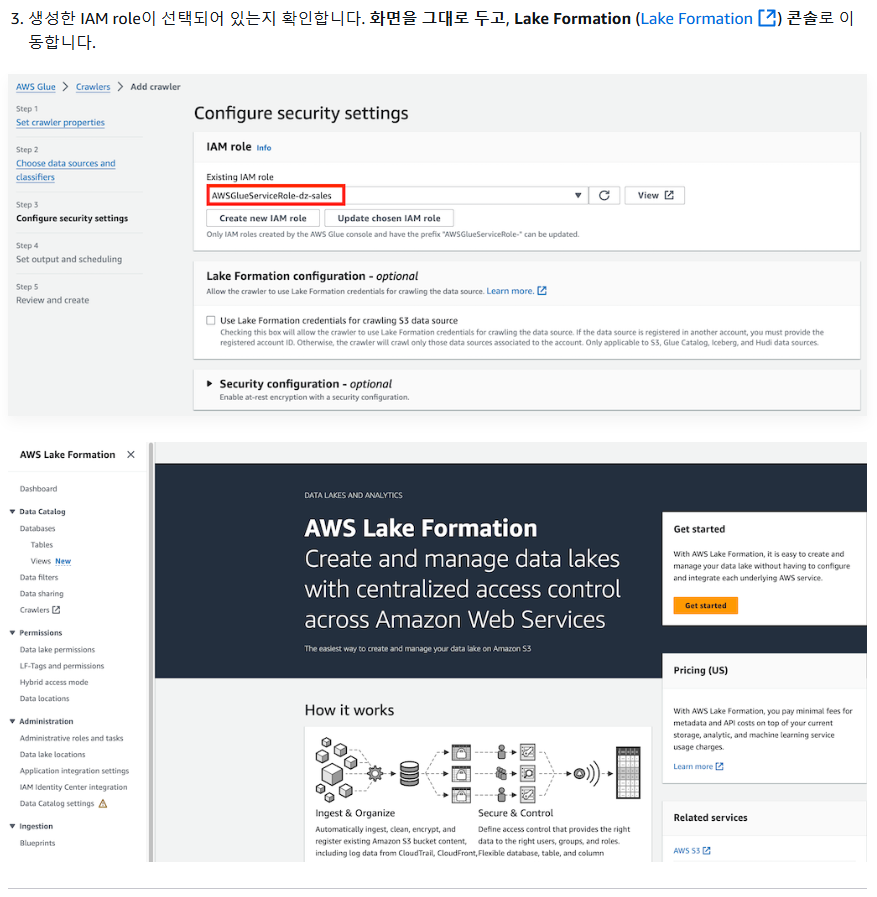
2-5 Lake Formation 권한 설정
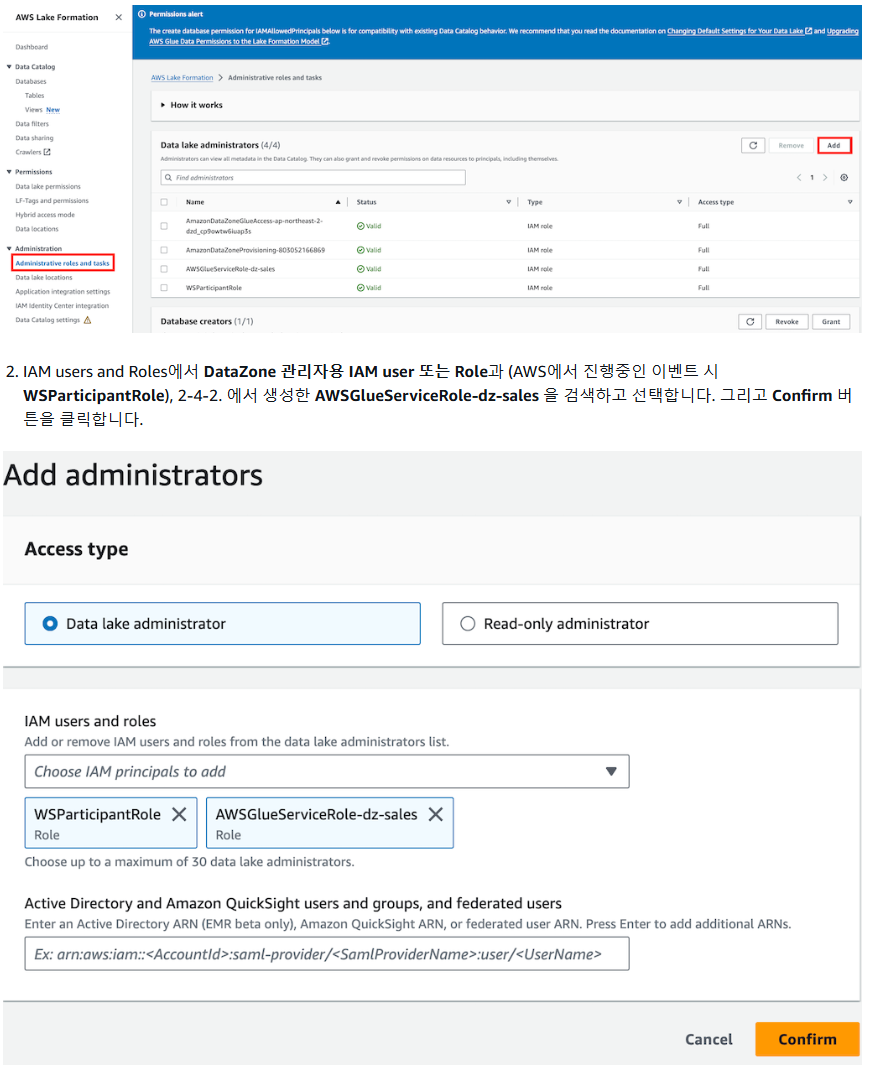
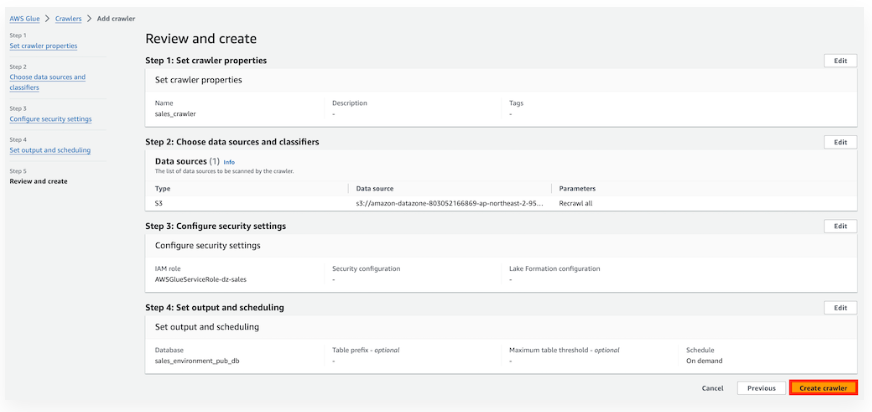
2-6) Crawler 생성 : 타겟 db 설정 및 생성

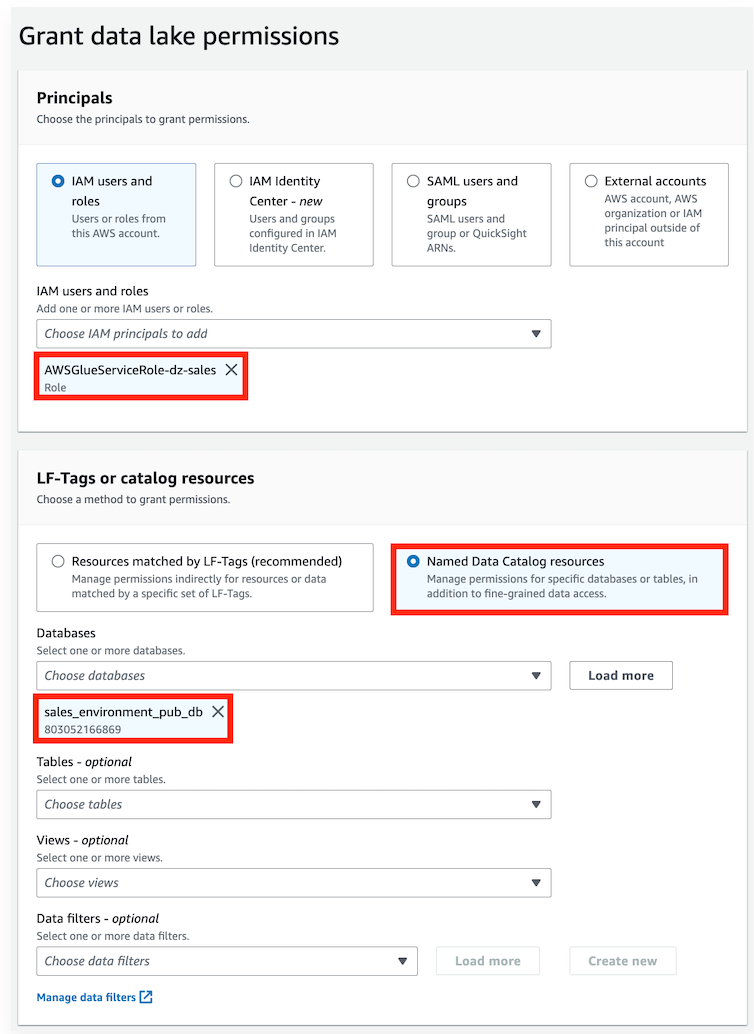
2-7) AWS Lake Formation 권한 추가 (Crawler 권한)


2-8) Crawler 실행

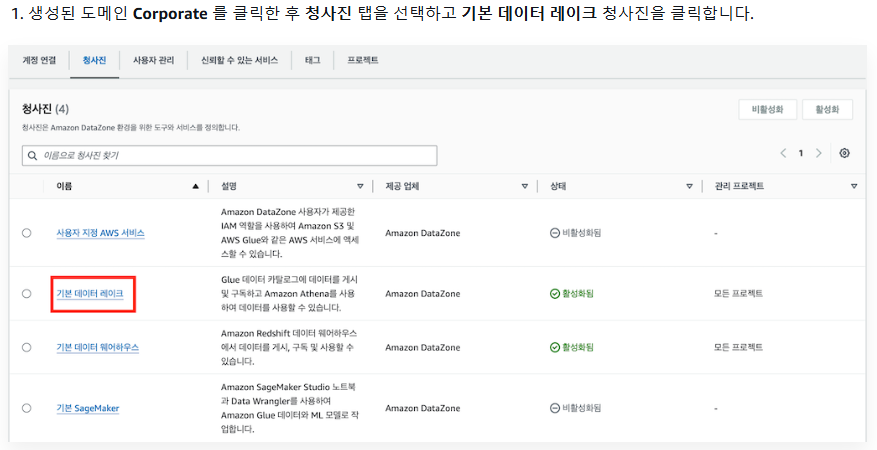
5. 메타데이터 설정

1) Glue Table 데이터 반영
1-1) 데이터 세트 가져오기
- AWS 관리 콘솔에서 DataZone 검색 -> 도메인 보기 -> 도메인 클릭 -> 데이터 포털 진입 -> 왼쪽 위 sales 클릭
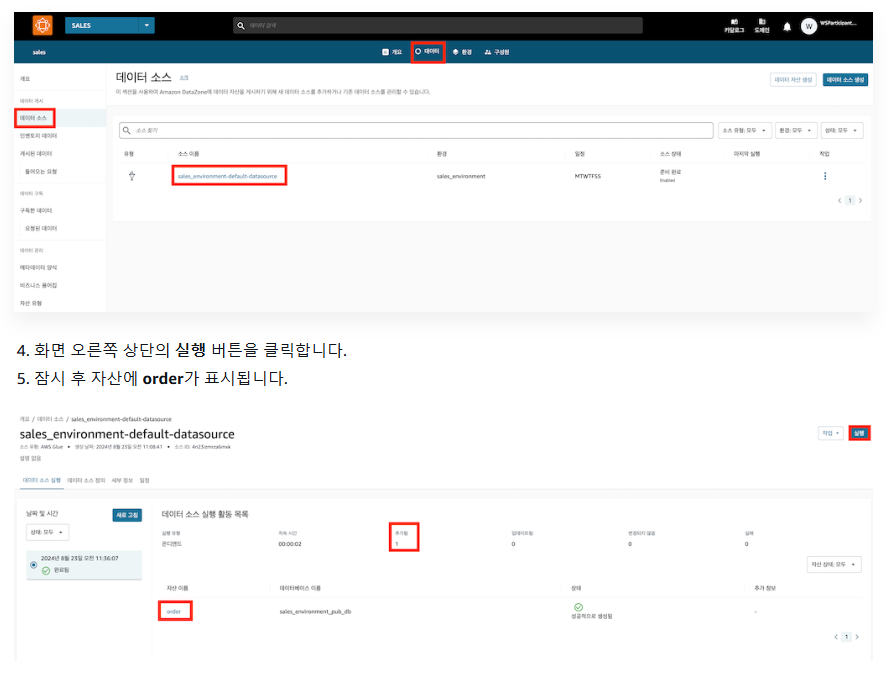
1-2) 메타데이터 반영
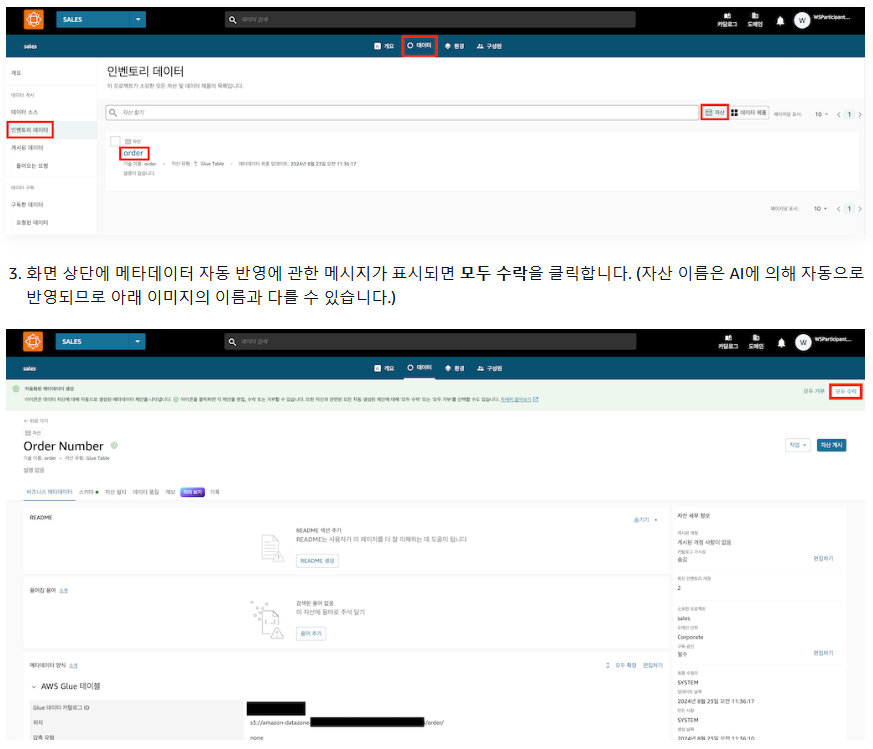
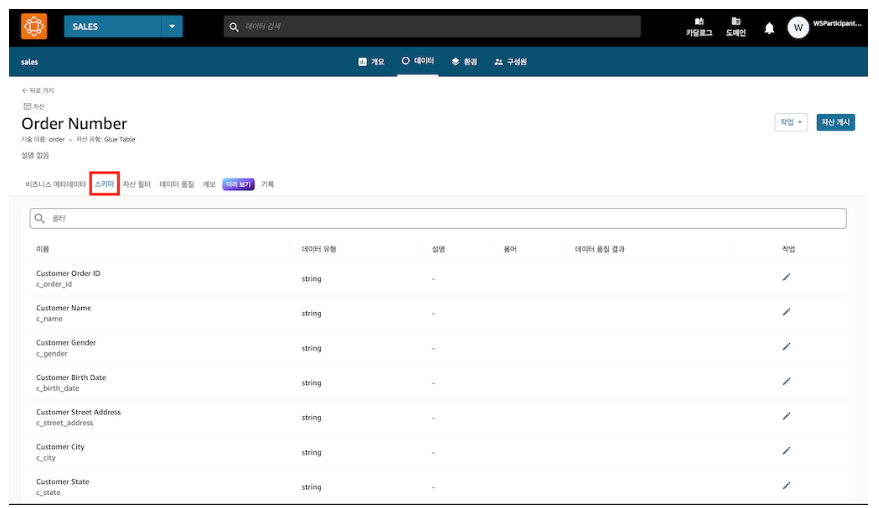
=> 스키마 탭에서 자동 반영된 것을 확인
2. 비즈니스 용어집 설정
2-1) 비즈니스 용어집 작성 화면으로 이동
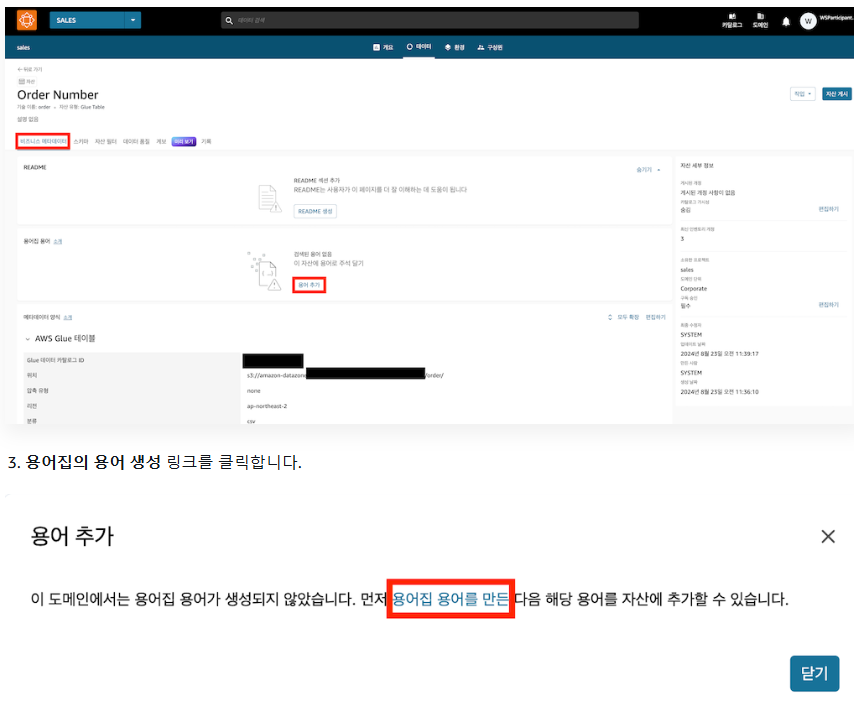

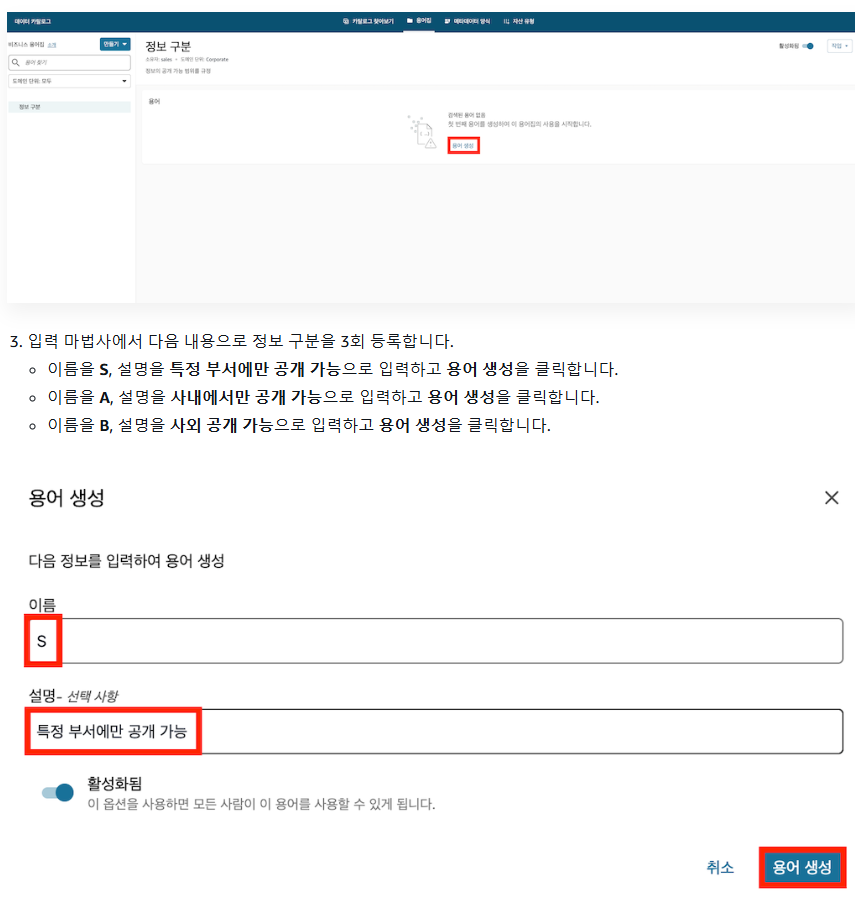
2-2) 비즈니스 용어집으로 '정보구분' 등록


2-3) 비즈니스 용어집으로 '판매 지역' 등록
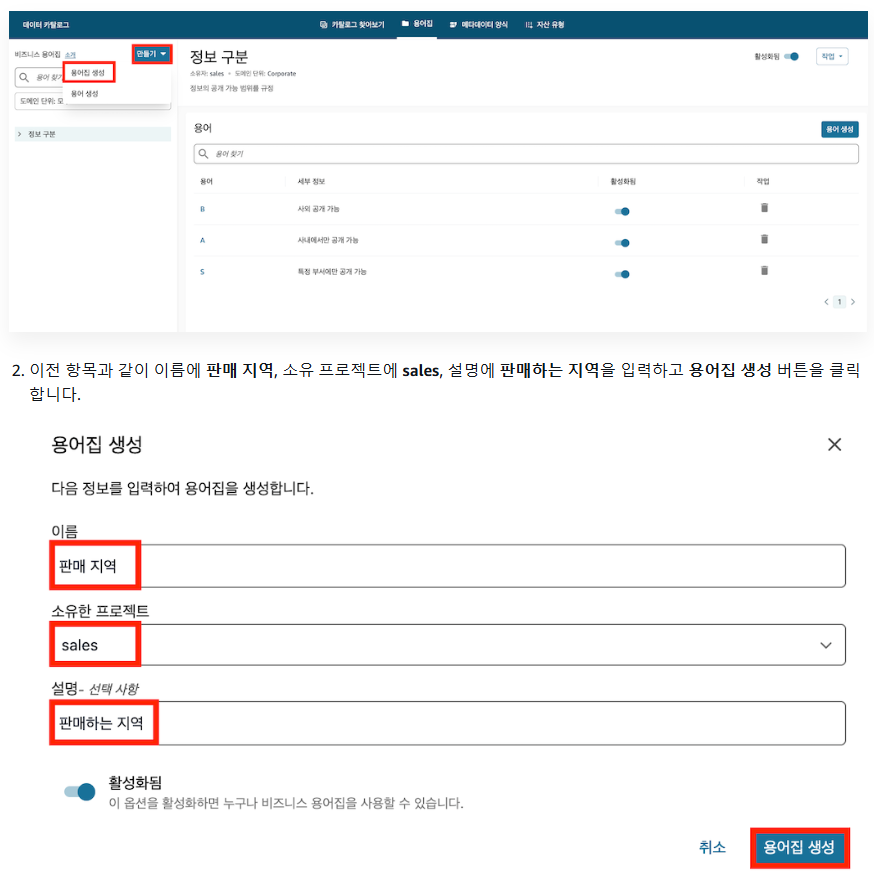

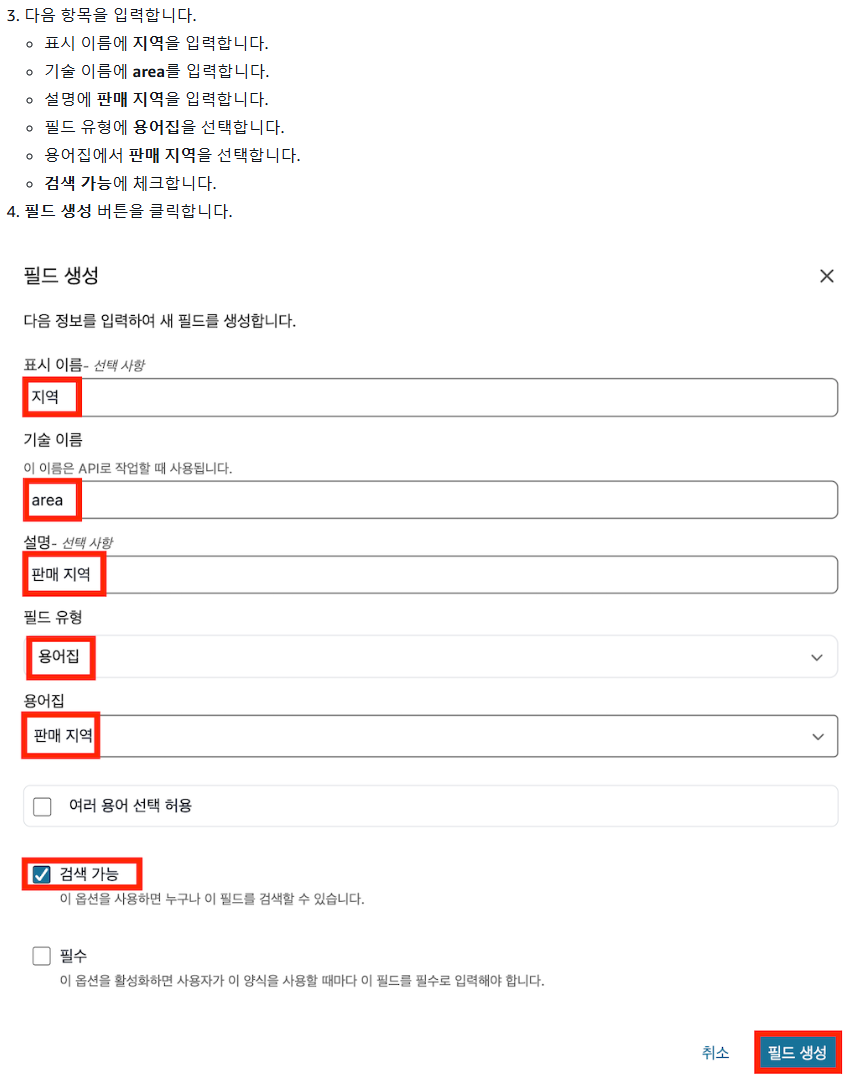
3. 메타데이터 양식 입력
3-1) 메타데이터 양식 작성 화면으로 이동

3-2) 메타데이터 양식에 '세일즈 메타데이터' 등록 -1 (판매 지역 용어집)


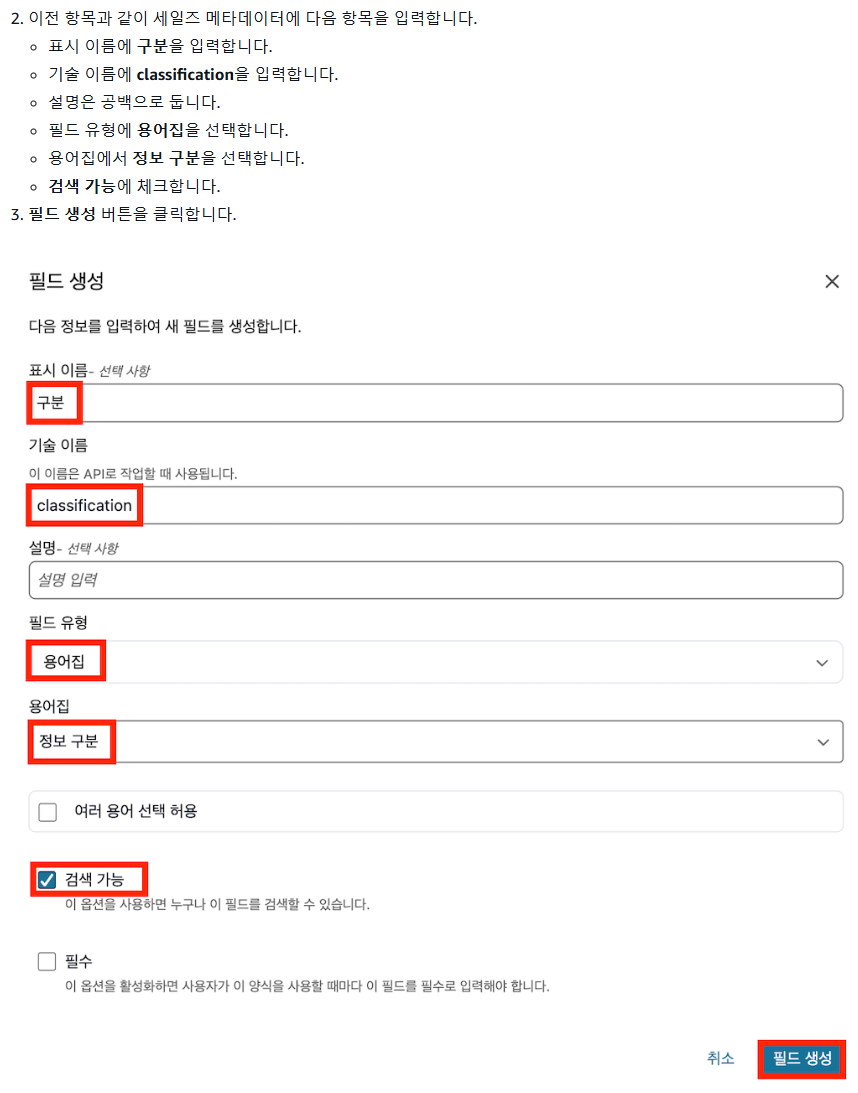
3-3) 메타데이터 양식에 '세일즈 메타데이터' 등록 -2 (정보구분 용어집)

3-4) 메타데이터 양식 활성화

6. Amazon DataZone에서 데이터 게시

1. 게시 작업 실행
1-1) 데이터 게시 - 1
- Sales에서 추가
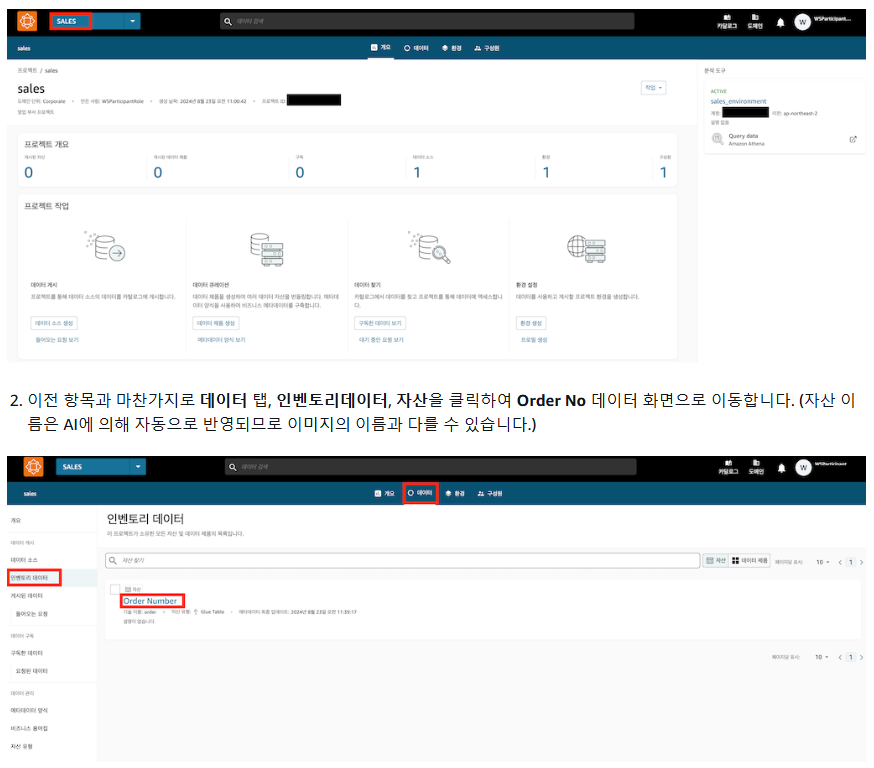
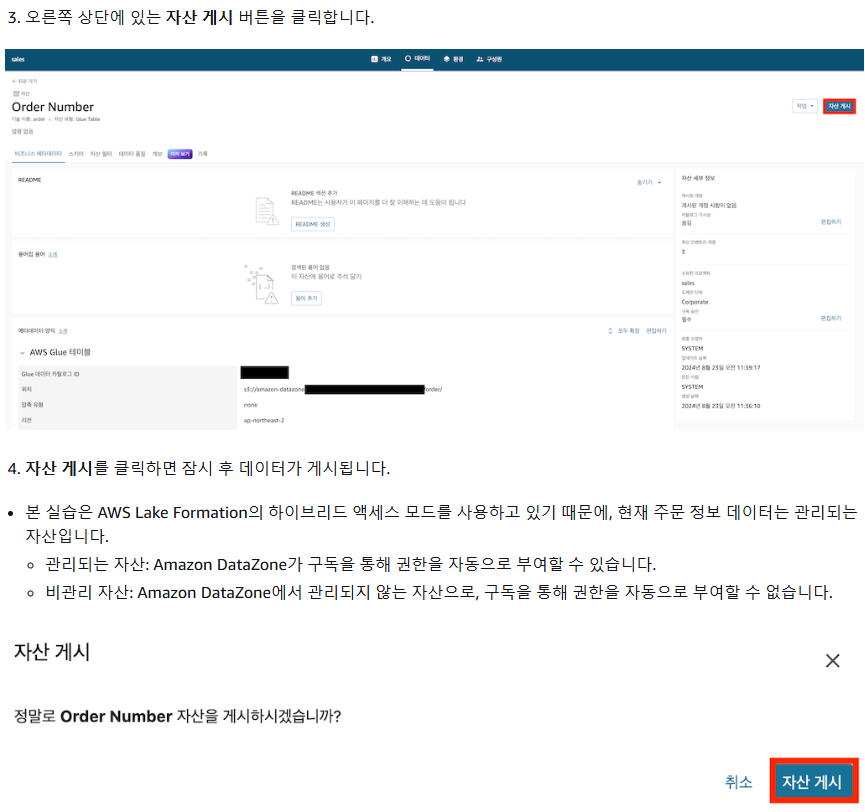
- 이때 경고 메세지(비관리형 자산)가 발생한다면 AWS Lake Formation 권한 설정을 진행한다.
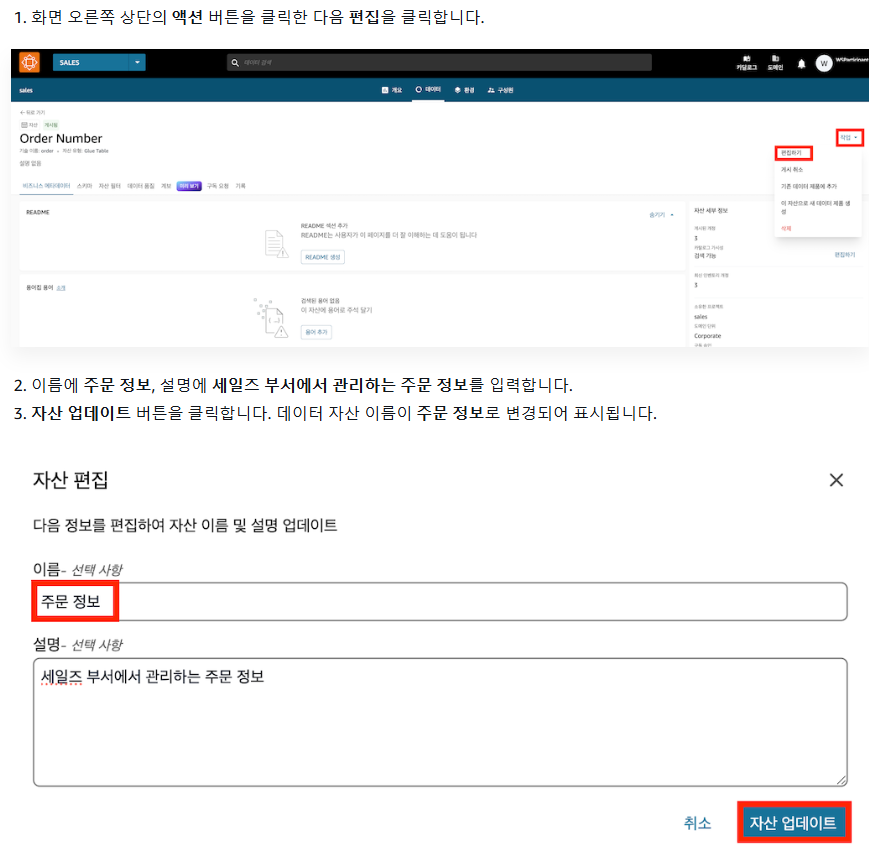
1-2) 데이터 카탈로그에 정보 추가
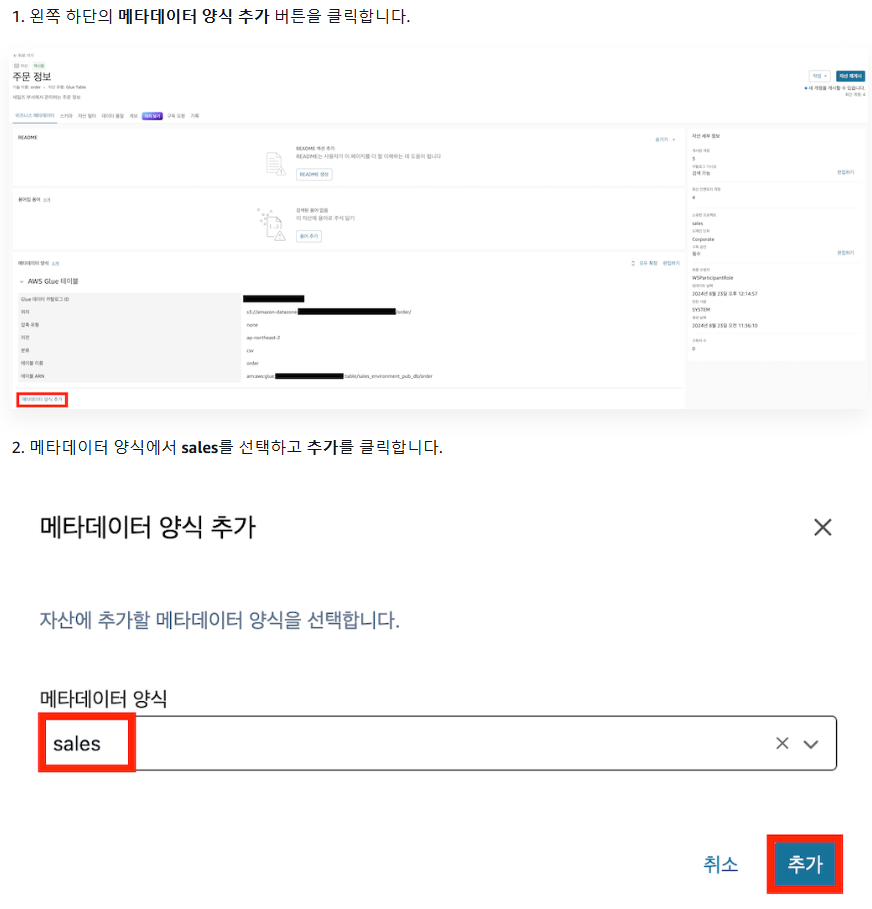
1-3) 데이터 카탈로그에 메타데이터 추가
1-4) 데이터 카탈로그의 메타데이터 양식 편집

1-5) 데이터 카탈로그의 스키마 편집 및 반영


7. 소비자 프로젝트 생성 (여기부터 예상 사용자 : 소비자)
1. 소비자 프로젝트 생성


2. 환경 프로필 생성


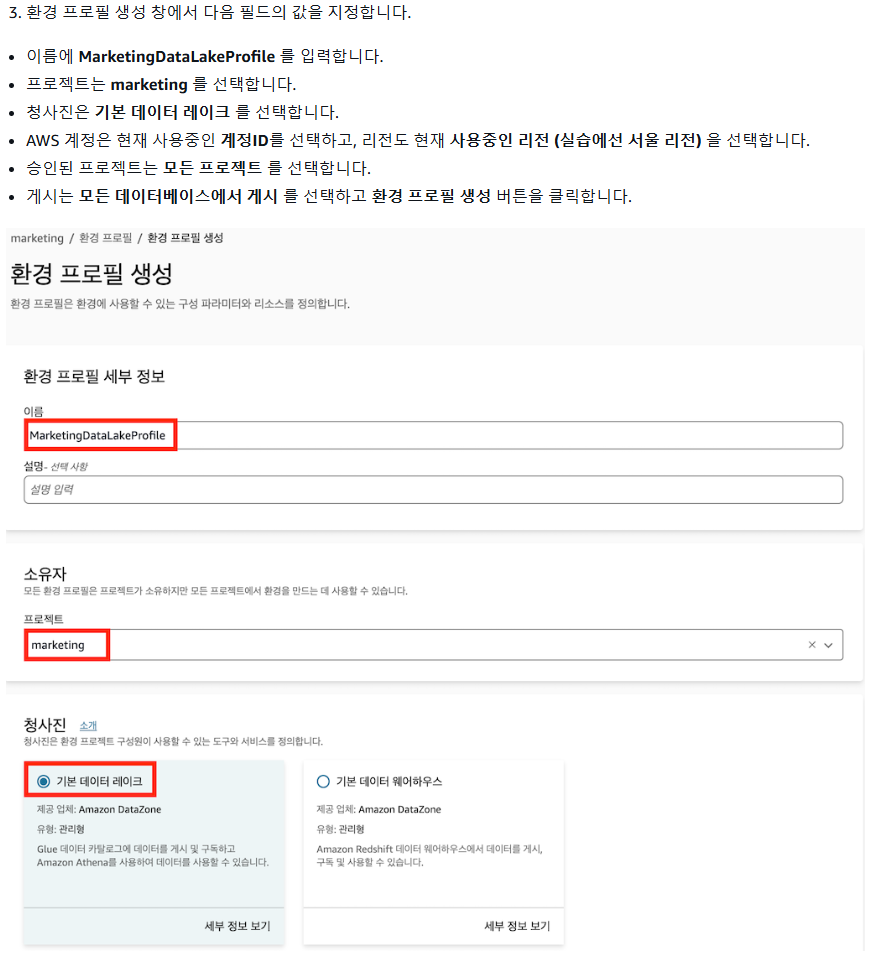

3. 환경 생성

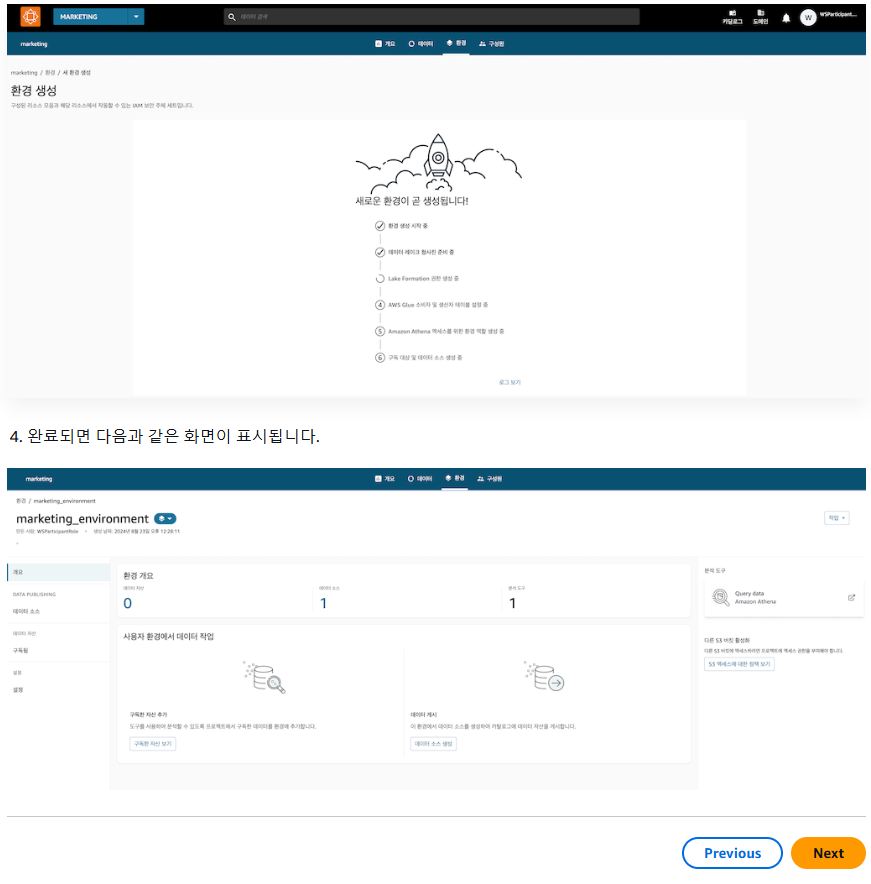
8. 게시된 데이터 자산을 소비자로 구독
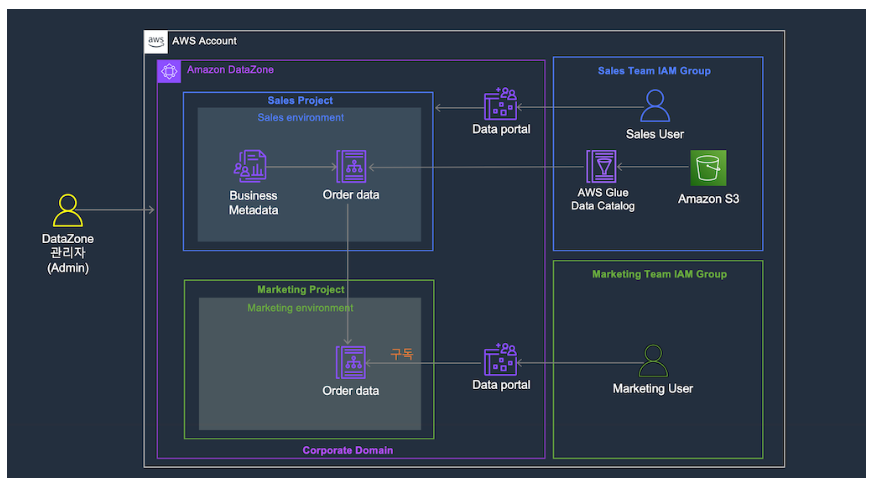
1. 데이터 검색
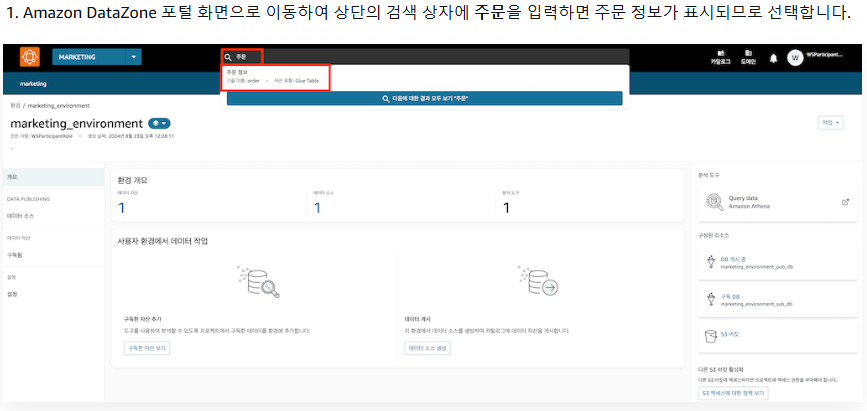

2. 데이터 구독 요청

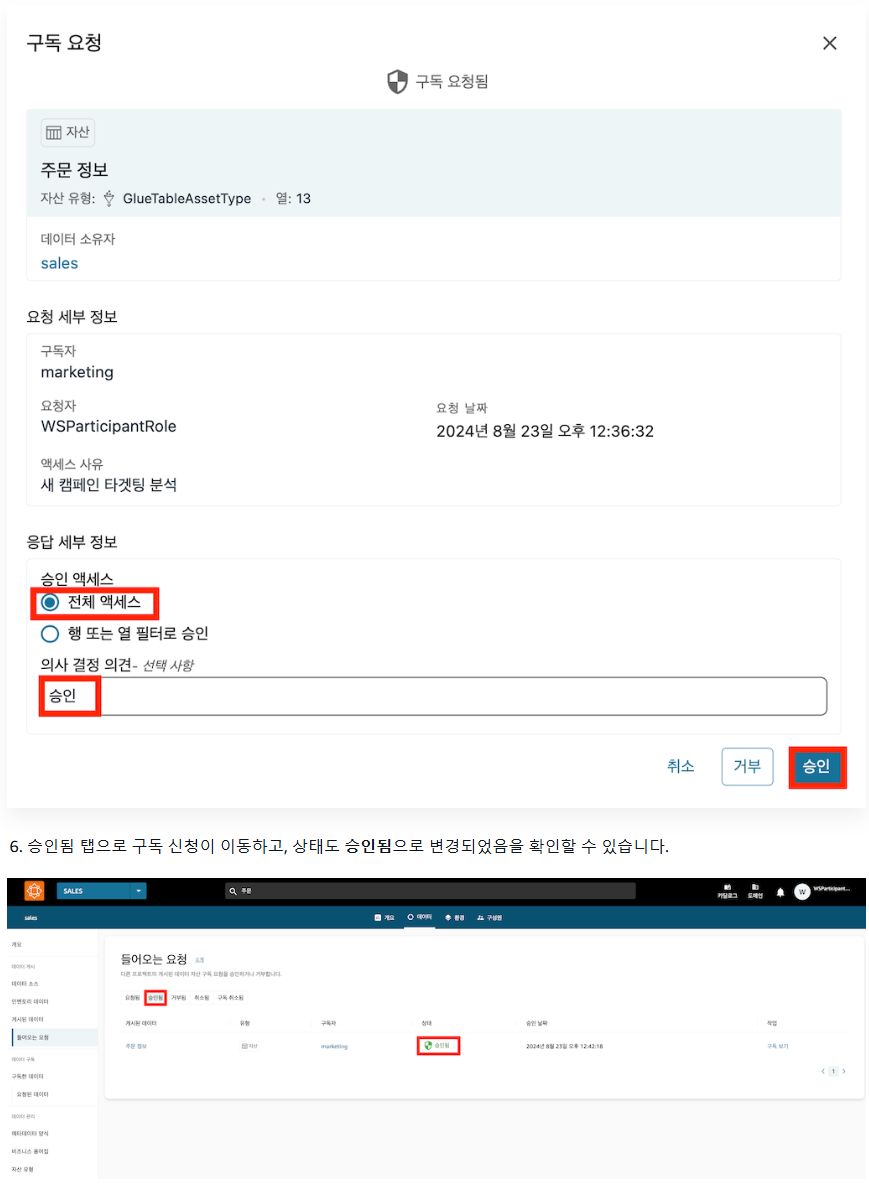
9. 게시한 데이터에 대해 생산자가 소비자의 엑세스 승인
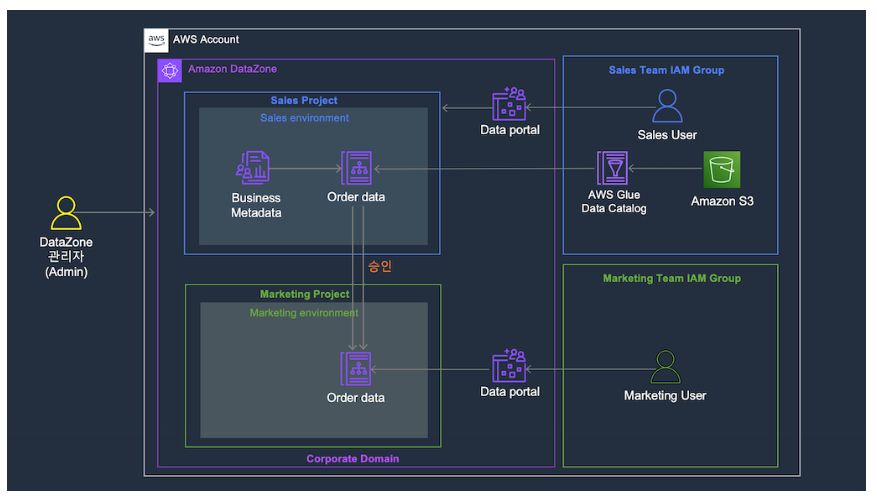
1. 구독 요청 확인

10. 데이터 생산자가 게시한 데이터 세트를 데이터 소비자가 Amazon Athena에서 분석
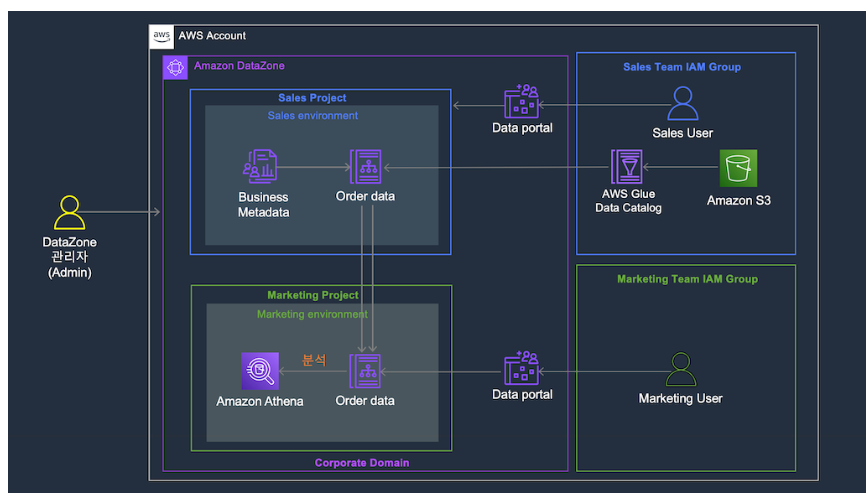
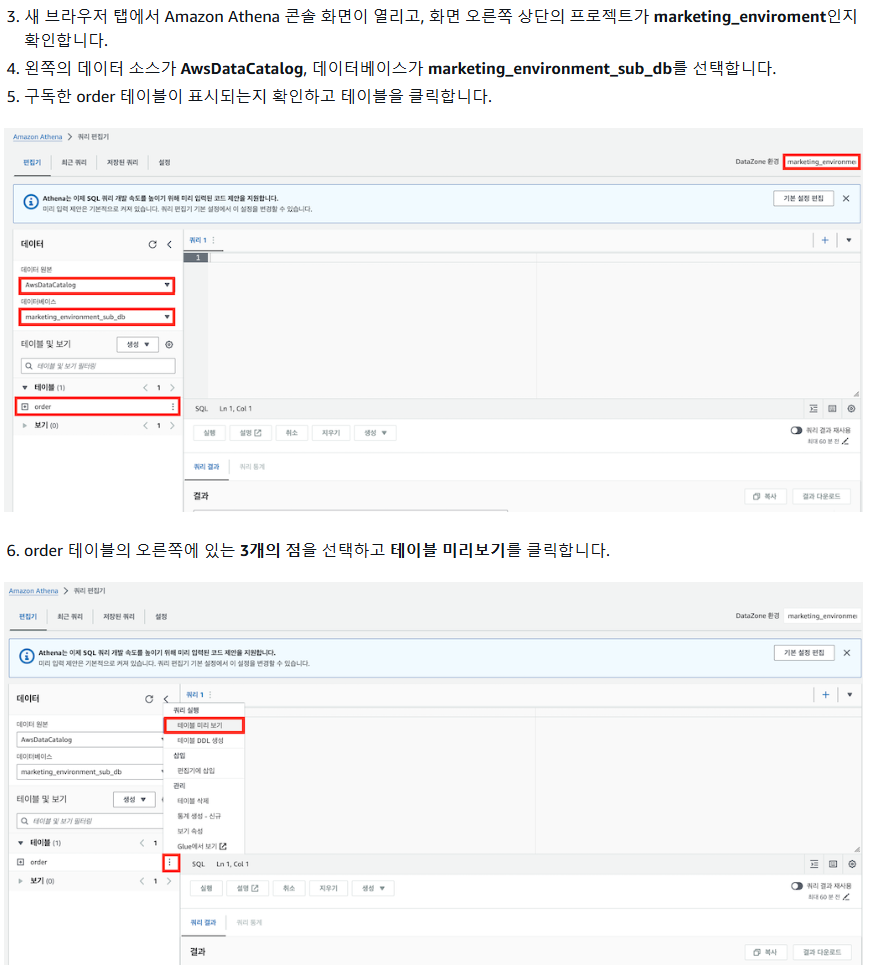
1. 구독 승인 확인
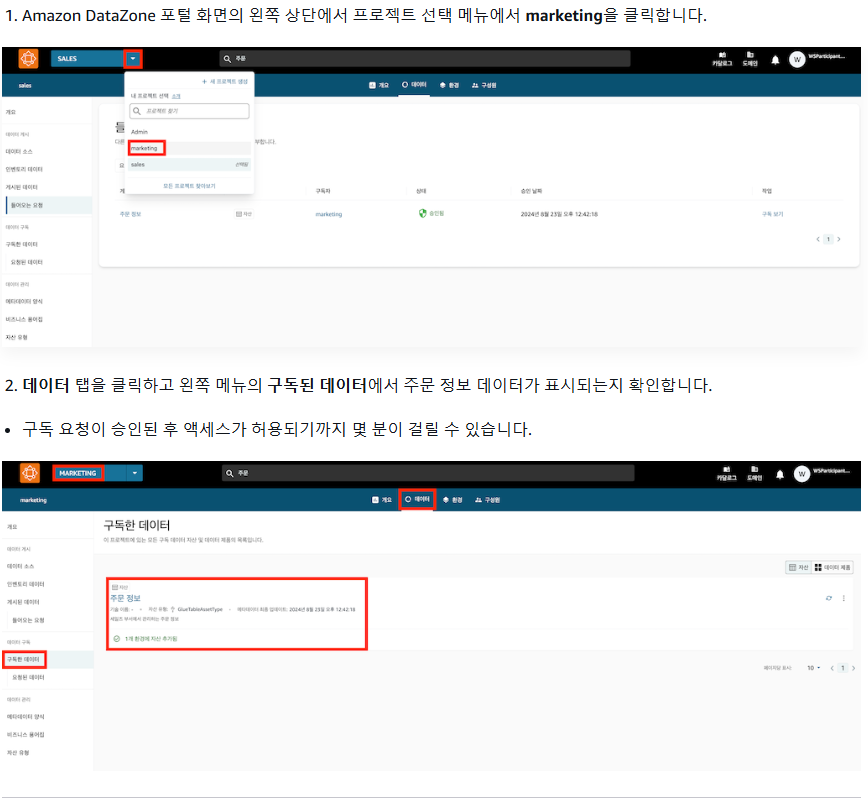
2. 데이터 표시


'Study > seSAC 금천 4기' 카테고리의 다른 글
| 클라우드_7일차_241014 (0) | 2024.10.31 |
|---|---|
| 클라우드_6일차_241011 (1) | 2024.10.31 |
| DevOps/Scrum 특강_241024~241025 (1) | 2024.10.25 |
| 이노그리드 CI/CD 특강_241022 (0) | 2024.10.23 |
| 클라우드_4일차_241008 (1) | 2024.10.15 |